The Pursuit of Instant Pushes
At Forza Football we strive to provide our apps users with the best possible experience, and lightning-fast push notifications is one of its aspects.

This photo (by Argonne National Laboratory) shows Cherenkov radiation glowing in the core of the Advanced Test Reactor. It’s emitted when a charged particle passes through a dielectric medium at a speed greater than the phase velocity of light in that medium.
My name is Aleksei and I spent most of last year building a new push notification system.
This blog post tells an introductory story of why it was needed, how it operates today, the migration path to the new system, and what the plans for the future are.
From an extremely high view, each push system consists of two logical parts: subscription tracking and notification sending.
Overview of our legacy system
The legacy push system is an integral part of a much bigger Ruby on Rails application, which is responsible for many more things besides push notifications handling.
Let’s take a closer look at it.
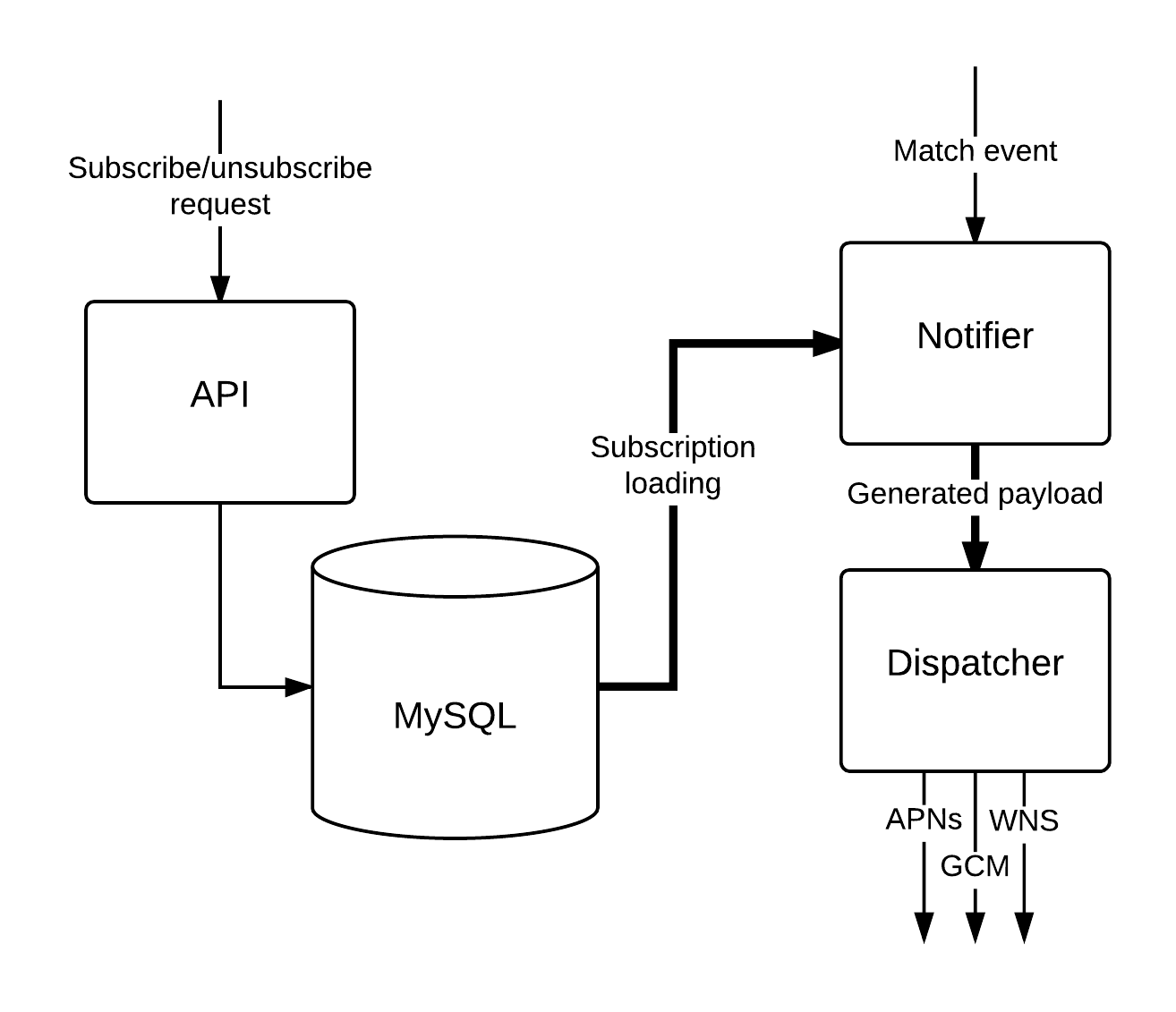
Subscription tracking
There is an API for handling subscribe/unsubscribe HTTP requests. Each request goes through a validation step and then subscriptions get inserted/deleted.
Before going further, I should explain how subscriptions look like. Every subscription contains:
device_token– an identifier in the specific vendor servicesubject– match, team, or leaguetopic– the matter of interest:"match_reminder","goal", etc.languagecountry
For instance, having the following subscription:
| device_token | xfL3k6QxHagFNf8Y01a |
| subject | team, 42 |
| topic | goal |
| language | en |
| country | SE |
We know that someone from Sweden, who speaks English, wants to receive a notification every time their favourite team scores a goal.
Notification sending
The process of sending notifications starts when a match reminder is generated, an event has happened during the football match, or a transfer rumour is received. Notifier loads all the relevant subscriptions, filters out token duplicates, removes muted devices, and as the last step builds translated messages (sometimes limiting selection to specific countries). Yes, we have to deal with token duplicates, since an individual user could be subscribed to both teams in a single match (also to a league).
After all these steps, the generated payload is sent to Dispatcher, which does the actual sending to the particular vendor service (Apple Push Notification, Google Cloud Messaging, or Windows Push Notification), and that’s the moment when users start to receive their notifications.
Slow pushes are slow
After having successfully used this setup for a long time we have reached a point when notification sending time has increased unacceptably.
For instance, it could take a few minutes, depending on application load, to send a push notification to 1 million subscribers.
Quick investigation has showed that it is all due to Notifier being extremely slow in loading the relevant subscriptions.
This was caused by the nature of the query (which included many JOIN expressions) and by the big size of the whole data set.
An attempt to fix the problem had already been done: subscribers sharding was introduced and subscribers querying was moved to a slave machine with a fancy index. There was a strong need to replace MySQL with something more appropriate (and change the data model). Ideally it should have allowed us to parallelize subscriptions handling (translation, country filtering, etc.) in some way, instead of doing it sequentially.
There was only one problem: too many data stores to choose from. Of course, we had to do research to pick the right one, so I limited the choice to a handful of databases (some I’ve worked with previously, some I selected based on their storage model and plenty of articles). I usually say “let’s think about future in the future”, but this wasn’t that case, thus I went with a 200 million subscriptions sample data set measuring 4 million subscriptions extraction. The process was conceptually simple but rather time consuming, it took about two months in total to pick a suitable database: Cassandra.
Cassandra data modeling
There are many articles written on this topic, however one rule is worth to repeat on every occasion: model around your queries. This leads to data duplication and a heavier write load, which is a preferred tradeoff in Cassandra.
The new push system operates with two tables in Cassandra: one to handle subscription tracking and another one for notification sending.
Both tables leverage compound primary key to store subscriptions which belongs to the same topic and subject sequentially on disk on a single node (plus replicas). It makes reads extremely efficient.
The role of the second table is to store normalized subscriptions. I mentioned previously, somebody can freely have intersected subscriptions, therefore this table effectively removes the burden of token duplicates handling during notification sending.
Moving to the new system
Now our new push system has got three specialized components built around Cassandra database. These components are written in Elixir.
For the inter-system data exchange we use MessagePack format (with Msgpax library) throughout the system. It is much faster than JSON, and has smaller footprint.
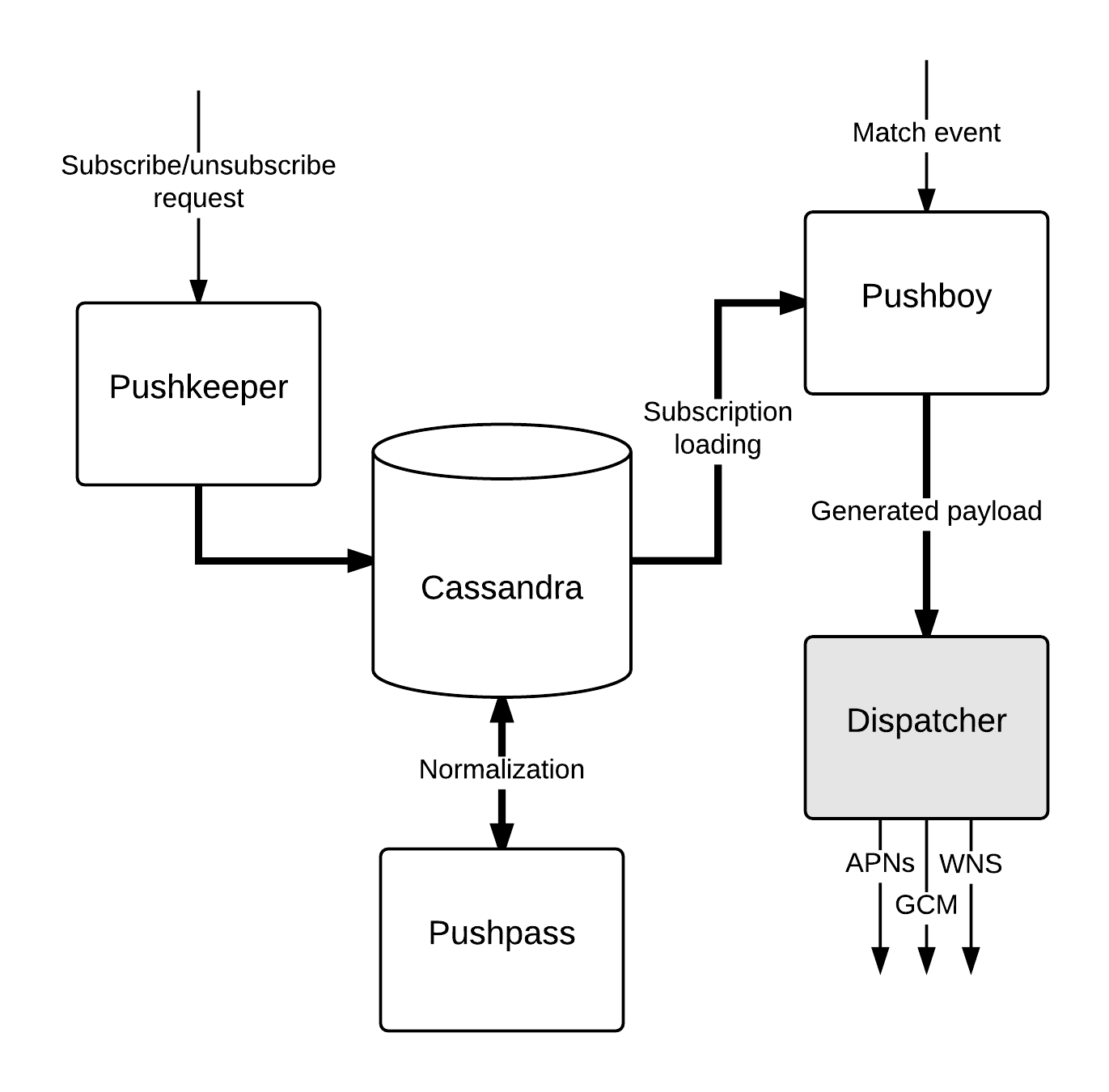
Subscription tracking
Besides the old API we have the Pushkeeper application, which is responsible for managing subscriptions, and it also took responsibility of feedback handling, which isn’t depicted. API operates as previously to support the legacy system, and also duplicates incoming requests to Pushkeeper to allow gradual migration to the new system.
Notification sending
The Pushboy application is replacing Notifier: it does the same tasks (loading subscriptions, performing messages translation, etc.). However, there is one important difference: subscriptions are already normalized, and Pushboy effectively streams them out of the Cassandra table. It means that users start to receive their notificatins right away.
The Pushpass application is a middleware between the former two, which is responsible for data normalization, that is, filtering out token duplicates and populating the specialized table.
Measure all the things
Migration to new systems is hard. To verify that the new system works as expected, we run it in parallel with the legacy system for about a half year, performing all operations except the very last step - sending data to vendor services. Only a limited set of test devices has been whitelisted. This helped us to refine deployment process, failure recovery mechanism, and of course, to measure all the things.
Our metrics system (which deserves its own blog post) was actually built from scratch during the migration to the new push system. I’ll just briefly mention some tools, libraries, and technologies we use for metrics: applications report metrics via Fluxter library to locally installed Telegraf agent, which sends them further to InfluxDB store.
According to a vast range of metrics the new system performs great, let’s see how long it takes to send a notification to 1.3 million subscribers.
The legacy system requires 40 seconds to prepare payload, and an additional 5 seconds to dispatch it.
The new system finishes sending in 16 seconds, and this is in a streaming way: this means that a half of subscribers will receive their notification in 8 seconds.
Bottleneck shifts to other place
Components of the new system reside in one datacenter while the legacy system is in another one (yes, one more migration, we’re moving to Amazon Web Services cloud). This quite badly affects the request time for sending generated payload to Dispatcher. In addition to that, Pushboy produces hundreds of such requests per second.
In fact, Pushboy finishes processing as fast as the slowest subscriptions chunk being processed in Dispatcher.
Long live the new system!
Since last month, we are running new push system in production for some particular notification topics.
Besides the pure performance improvement, there is a bunch of things improved:
- No more “MySQL as a queue” anti-pattern, which brings locking issues and data growth control problem.
- Notification sending executes in parallel, in a streaming manner.
- Main Ruby on Rails application no longer affects push system operation (for example, CPU stealing was a noticeable problem before), and its complexity has decreased.
- Tiny targeted components make maintenance easier.
- Started to practice canary deployments.
- We simply need less resources than was required previously.
Elixir matters a lot for the system
Starting with the programmer happiness, there are many, much more pragmatic reasons to choose Elixir.
Elixir’s compiler is wonderful. It is smart, fast, and incredibly helpful. It actively helps in the elimination of bugs early on in the software cycle.
Erlang Runtime System enabled us to build highly concurrent system with strong fault tolerant characteristics. It provides better introspection capabilities and live system debugging.
Furthermore, we utilize distributed setup for several things, for example: to reduce the probability of duplicated delivery, or to coordinate subscriptions normalization.
Beyond the speed of light
Things indeed improved but there are still many left:
- Complete switch to the new system in coming weeks.
- Replace Dispatcher with the Pushgate application, which is located in the same datacenter.
- Introduce API v2, revised and enhanced.
In addition, we have quite ambitious plan to release several Elixir libraries. Stay tuned.