Binary parsing optimizations in Elixir
Binary parsing is a significant part of almost every application: interactions with databases, data-interchange formats, integers and datetimes in string representation, etc. Making optimizations to those domains might result in substantial speed-up across the whole application.

In the previous blog post I mentioned that we intensively use the MessagePack format where possible (soon our mobile clients start using it too). Comparing to JSON for example, it is much faster, has smaller footprint, and it shows better compression speed and ratio.
In this article I will be using the MessagePack library of our choice—Msgpax—to showcase optimizations you could apply to your implementations of binary parsing.
Measuring the impact
The actual outcome of any optimizations to binary parsing really depends on the data being parsed. For our showcase we will be using the following, somewhat close to reality, data:
inner_map =
{0.0, [true, -129]}
|> Stream.iterate(fn {key, val} -> {key + 1, val} end)
|> Stream.map(fn {key, val} -> {Float.to_string(key), [key | val]} end)
|> Enum.take(20)
|> Map.new()
content =
%{
"foobar" => nil,
"baz" => List.duplicate(9001, 20),
"plugh" => inner_map
}
|> List.duplicate(20)
Also we are going to use a rather simple and comprehensible benchmarking script:
payload = Msgpax.pack!(content, iodata: false)
run_count = 10_000
for _ <- 1..1000 do
Msgpax.unpack(payload)
end
total_spent = Enum.reduce(1..run_count, 0, fn _, result ->
{run_spent, _result} = :timer.tc(Msgpax, :unpack, [payload])
result + run_spent
end)
IO.puts(total_spent / run_count) # microseconds per run
Before getting to the applied optimizations it is worth checking the pre-optimized version of Msgpax. For completeness, let’s include our current go-to JSON library—Jason, and yet the most popular JSON library on Hex—Poison.
Elixir 1.5.2 and OTP 20.1.5 yield:
| Msgpax 1.1.0 | 417.8994 |
| Jason 1.0.0 | 564.4407 |
| Poison 3.1.0 | 671.3923 |
And the optimized Msgpax gives the powerful 228.1887 μs. It is a 45% speed-up.
How did we get there?
The rocky road of the single match context optimization
In general, every binary matching (<<...>>) generates a match context.
Also for each part that accessed out of a binary a sub binary is created, that is a reference to that accessed part of the binary. This makes binary matching relatively cheap because the actual binary data is never copied.
Nevertheless, the Erlang compiler avoids generating code that creates a sub binary if the compiler sees that shortly afterwards a new match context is created and the sub binary is discarded. Instead of creating a sub binary, the initial match context is kept.
The compiler can point out the places where such optimiation could be applied (or have already been applied) by using the bin_opt_info option:
ERL_COMPILER_OPTIONS=bin_opt_info mix run lib/msgpax/unpacker.ex
It will produce dozens of NOT OPTIMIZED warnings, that could be split into two types:
-
sub binary is used or returned
-
called function … does not begin with a suitable binary matching instruction
The first type literally means what the warning says, thus creating a sub binary cannot be avoided. This is the code that generates such warning:
def unpack(<<0xC3, value, rest::bytes>>) do
{value, rest}
end
In the code above, the rest variable represents that returned sub binary.
In some cases it is indeed a desired behaviour, but not when such function is called in a recursive manner:
defp unpack_list(<<>>, 0, result) do
result
end
defp unpack_list(rest, length, result) do
{value, rest} = unpack(rest)
unpack_list(rest, length - 1, [value | result])
end
For example, when we unpack a 5-element list the unpack_list/4 function will be called 5 times,
each time creating a new match context and a new sub binary, even if the only use of the sub binary is the next call binary matching (hence its creation can be avoided and the match context can be reused).
Without our help the compiler could not understand that intention. Continuous parsing is the way to get the code optimized:
def unpack(<<buffer::bytes>>) do
unpack(buffer, [], 1)
end
defp unpack(<<>>, [value], 0) do
value
end
defp unpack(<<0xC3, value, rest::bytes>>, result, count) do
unpack(rest, [value | result], count - 1)
end
With this code the optimization works, however, only if the unpack/2 clauses do not produce the second type of NOT OPTIMIZED warnings.
-
called function … does not begin with a suitable binary matching instruction
To resolve the warning each clause of the unpack/2 function must start with a binary matching, that is, the first argument is <<...>>.
Note that with continuous parsing we also were able to avoid 2-element tuple creation.
Starting with OTP 21, the compiler might reorder function arguments to fix the warning and make the optimization happen (see the pull request).
Diving deeper for more optimizations
Keeping a single match context when parsing certainly increases its speed. Yet there are more things to consider. Unnecessary check elimination is one of such.
For example, in the previous code snippet the ::bytes part of the binary matching is not strictly necessary.
It adds an additional check to ensure that rest is divisible by 8.
Changing ::bytes to ::bits will eliminates the check (28947f9).
To observe the result of this change let’s inspect the produced assembler code. The following command should output it to the Elixir.Msgpax.Unpacker.S file:
mix run --eval "beam = :code.which(Msgpax.Unpacker); {:ok, {_, [abstract_code: {:raw_abstract_v1, abstract_code}]}} = :beam_lib.chunks(beam, [:abstract_code]); :compile.forms(abstract_code, [:S])"
The ::bits usage will result in the eliminated bs_test_unit bytecode instructions in the assembly.
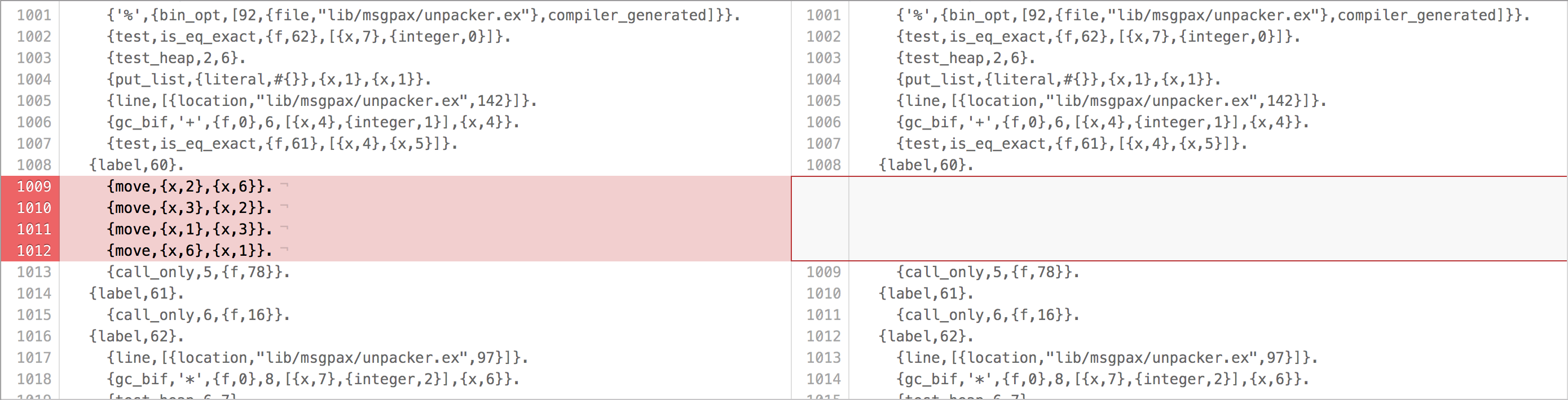
Keeping the argument order intact also helps with the instruction elimination.
The 69cd8df commit ensures that the argument order in unpack_continue/6 and unpack_continue/5 is the same.
This makes the following difference to the produced assembly:
Another type of optimizations is function clauses reordering. In fact, the compiler does function clauses reordering when possible. But many times it requires manual work to receive faster code.
Putting higher-probability clauses to the top (or the opposite—lower-probability clauses to the bottom) can give better speed. Though changes like that, I believe, warrant regular benchmarking and the produced assembler code inspection.
For Msgpax there were 2 attempts of function clauses reordering (be19258, and 1955c5e)—both giving noticeable boost.
But ultimately the code inlining gave much better outcome.
The top function clause was integrated into several places where it actually belongs to (81330c3).
After that the :inline directive has helped to get rid of the code duplication (6eacf81).
Wrapping up
All the aforementioned optimization were bundled into a single pull request to Msgpax.
I think many kinds of applications would benefit from binary parsing optimizations. And the compiler has all the necessary tools to assist you.
There are also more examples of these optimizations in the wild:
- Integer.parse/2 in Elixir
- Decoding in Xandra—our Cassandra driver for Elixir
I’m going to close the article with the step by step parsing time progress:
| 4ac16cf (pre-optimized) | 417.8994 |
| 3ad47e2…3d3f5b5 | 321.7947 |
| 171faab | 311.3362 |
| 4b2dba7 | 304.8067 |
| 5e3a213 | 313.7435 |
| 08549bf | 334.0085 |
| 1955c5e (function clauses reordering) | 266.7469 |
| f22686b | 262.2508 |
| 81330c3 (function clause inlining) | 239.2266 |
| 2eb1a9f (unnecessary check elimination) | 229.2112 |
| 69cd8df (keeping the argument order) | 228.1887 |
Until the next one. 🚀